
10·
6 days agoAh, strange.
I’ve never had any issues, but I also haven’t used it in a while.
Might be related to transcoding/sub-burning? https://github.com/jellyfin/jellyfin-web/issues/6210
Ah, strange.
I’ve never had any issues, but I also haven’t used it in a while.
Might be related to transcoding/sub-burning? https://github.com/jellyfin/jellyfin-web/issues/6210
Jellyfin has much better Syncplay than plex
release announcement:

Been using nix to game on for 2 years. My config is a bit out of date, I haven’t really taken the time to update and optimize it.
helldivers 2 works great for me with nixos. Both native package and flatpak.
All storage is on a Ceph cluster with 2 or 3 disk/node replication. Files and databases are backed up using Velero and Barman to S3-compatible storage on the same cluster for versioning. Every night, those S3 buckets are synced and encrypted using rclone to a 10tb Hetzner Storage Box that keeps weekly snapshots.
Config files in my git repo:
https://codeberg.org/jlh/h5b/src/branch/main/argo/external_applications/velero-helm.yaml
https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/bitwarden/database.yaml
https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/backups
https://codeberg.org/jlh/h5b/src/branch/main/argo/custom_applications/rook-ceph
Bit more than 3 copies, but hdd storage is cheap. Majority of my storage is Jellyfin anyways, which doesn’t get backed up.
I’m working on setting up some small nvme nodes for the ceph cluster, which will allow me to move my nextcloud from hdd storage into its own S3 bucket with 4+2 erasure coding (aka raid 6). That will make it much faster and also its cut raw storage usage from 4x to 1.5x usable capacity
NTsync is not the same as Fsync, it allows for kernel acceleration of NT sync primitives, increasing speed over current wine/Proton builds.

if it ain’t broke don’t fix it. I’ve worked plenty of private sector jobs where they use COBOL somewhere in the company
You should use synapse. Dendrite is not intended for self-hosted homeservers. You will have an easier time with calling/rtc with synapse as well.
Here is a good example of how to set up a home server, which was shown off by the devs at fosdem last weekend:
Open AI Dublin could just legally pirate ChatGPT o1 once the trade war kicks off
14 yo’s were 6 when Trump’s first term started
Oh definitely, everything in kubernetes can be explained (and implemented) with decades-old technology.
The reason why Kubernetes is so special is that it automates it all in a very standardized way. All the vendors come together and support a single API for management which is very easy to write automation for.
There’s standard, well-documented “wizards” for creating databases, load-balancers, firewalls, WAFs, reverse proxies, etc. And the management for your containers is extremely robust and extensive with features like automated replicas, health checks, self-healing, 10 different kinds of storage drivers, cpu/memory/disk/gpu allocation, and declarative mountable config files. All of that on top of an extremely secure and standardized API.
With regard for eBPF being used for load-balancers, the company who writes that software, Isovalent, is one of the main maintainers of eBPF in the kernel. A lot of it was written just to support their Kubernetes Cilium CNI. It’s used, mainly, so that you can have systems with hundreds or thousands of containers on a single node, each with their own IP address and firewall, etc. IPtables was used for this before. But it started hitting a performance bottleneck for many systems. Everything is automated for you and open-source, so all the ops engineers benefit from the development work of the Isovalent team.
It definitely moves fast, though. I go to kubecon every year, and every year there’s a whole new set of technologies that were written in the last year lol
Ah, ok, yeah seems very custom. I guess it must predate Ingress.
No problem, good luck!
Ah, but your dns discovery and fail over isn’t using the built-in kubernetes Services? Is the nginx using Ingress-nginx or is it custom?
I would definitely look into Ingress or api-gateway, as these are two standards that the kubernetes developers are promoting for reverse proxies. Ingress is older and has more features for things like authentication, but API Gateway is more portable. Both APIs are implemented by a number of implementations, like Nginx, Traefik, Istio, and Project Contour.
It may also be worth creating a second Kubernetes cluster if you’re going to be migrating all the services. Flannel is quite old, and there are newer CNIs like Cilium that offer a lot more features like ebpf, ipv6, Wireguard, tracing, etc. (Cilium’s implementation of the Gateway API is bugger than other implementations though) Cillium is shaping up to be the new standard networking plugin for Kubernetes, and even Red Hat and AWS are starting to adopt it over their proprietary CNIs.
If you guys are in Europe and are looking for consultants, I freelance, and my employer also has a lot of Kubernetes consulting expertise.
ah ok
Ah, interesting. What kind of customization are you using CoreDNS for? If you don’t have Ingress/Gateway API for your HTTP traffic, Traefik is likely a good option for adopting it.
All containers in a pod share an IP, so you can just use localhost: https://www.baeldung.com/ops/kubernetes-pods-sidecar-containers
Between pods, the universal pattern is to add a Service for your pod(s), and just use the name of the service to connect to the pods the Service is tracking. Internally, the Service is a load-balancer, running on top of Kube-Proxy, or Cilium eBPF, and it tracks all the pods that match the correct labels. It also takes advantage of the Kubelet’s health checks to connect/disconnect dying pods. Kubedns/coredns resolves DNS names for all of the Services in the cluster, so you never have to use raw IP addresses in Kubernetes.
Go all out and register your container IPs on your router with BGP 😁
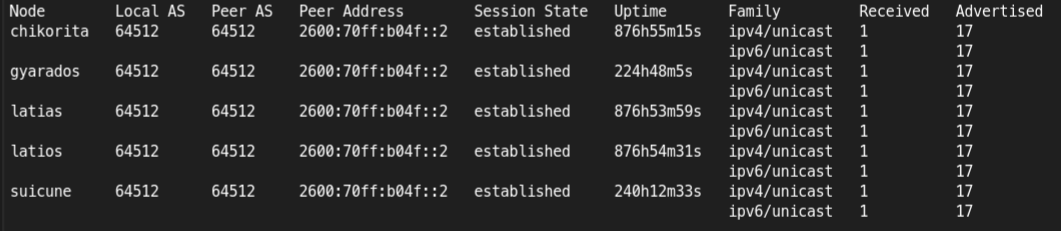
(This comment was sent over a route my automation created with BGP)
I’ve inherited it on production systems before, automated service discovery and certificate renewal is definitely what admins should have in 2025. I thought the label/annotation system it used on Docker had some ergonomics/documentation issues, but nothing serious.
It feels like it’s more meant for Docker/Podman though. On Kubernetes I use cert-manager and Gateway API+Project Contour. It does seem like Traefik has support for Gateway API too, so it’s probably a good choice for Kubernetes too?
Interesting. Feels like it lowers the skill ceiling a bit, but hopefully it makes the game more accessible to everyone.